
Парсинг сайта на Python
Сегодня мы будем парсить сайт на Python
для парсинга нам понадобятся следующие библиотеки :
urllib.request и BeautifulSoup
эти библиотеки нужно импортировать в проект
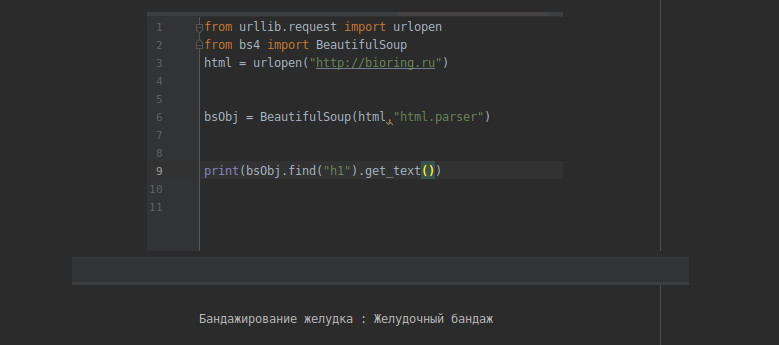
from urllib.request import urlopen
from bs4 import BeautifulSoup
далее мы инициализируем переменную html в которую сохраняем значение страницы которую парсим
html = urlopen("http://hernia.moscow")
затем следующей переменной мы присваиваем значение равное всему HTML содержимому страницы
bsObj = BeautifulSoup(html,"html.parser")
затем берем и из всего HTML содержимого выводим текст HTML тега h1
print(bsObj.find("h1").get_text())
результат который пойдет в консоль это и есть текст который хранится внутри тега h1
так-же мы можем посмотреть есть ли на странице фраза "грыжа" , если добавим еще одну строку в нашу программу
print(bsObj.find(text="грыжа"))

